

Live notebook
You can run this notebook in a live session ![]() or view it on Github.
or view it on Github.
Pattern matching#
Crystal orientations can be determined from experimental EBSD patterns by matching them to simulated patterns of known phases and orientations, see e.g. [Chen et al., 2015], [Nolze et al., 2016], [Foden et al., 2019].
In this tutorial, we perform dictionary indexing (DI) of a small nickel EBSD dataset. We use a dynamically simulated nickel master pattern from EMsoft found in the kikuchipy.data module. The master pattern has relatively low pixel resolution. We generate the pattern dictionary from a uniform grid of orientations with a fixed projection center (PC) followng [Singh and De Graef, 2016]. The true orientation is likely to fall in between grid points. This means that the lowest angular accuracy obtainable with DI has is bounded by the grid sampling resolution. However, we can improve upon each orientation solution by searching the space in between the grid points. We do this by maximizing the similarity between experimental and simulated patterns using numerical optimization algorithms. This is here called orientation refinement. We could instead keep the orientations fixed and let the PC parameters deviate from their fixed values used in the dictionary, here called projection center refinement. Finally, we can also refine both at the same time, here called orientation and projection center refinement. The need for orientation or orientation/PC refinement is discussed by e.g. [Singh et al., 2017], [Winkelmann et al., 2020], and [Pang et al., 2020].
The term pattern matching is here used for the combined approach of DI followed by refinement.
Before we can generate a dictionary of simulated patterns, we need a master pattern containing all possible scattering vectors for a candidate phase. This can be simulated using EMsoft ([Callahan and De Graef, 2013] and [Jackson et al., 2014]) and then read into kikuchipy.
First, we import libraries
[1]:
# Exchange inline for notebook or qt5 (from pyqt) for interactive plotting
%matplotlib inline
import tempfile
import matplotlib.pyplot as plt
import numpy as np
import hyperspy.api as hs
import kikuchipy as kp
from orix import sampling, plot, io
from orix.vector import Vector3d
plt.rcParams.update({"figure.facecolor": "w", "font.size": 15})
Load the small experimental nickel test data
[2]:
# Use kp.load("data.h5") to load your own data
s = kp.data.nickel_ebsd_large(allow_download=True) # External download
s
[2]:
<EBSD, title: patterns Scan 1, dimensions: (75, 55|60, 60)>
To obtain a good match, we must increase the signal-to-noise ratio. In this pattern matching analysis, the Kikuchi bands are considered the signal. The angle-dependent backscatter intensity, along with unwanted detector effects, are considered to be noise. See the pattern processing tutorial for further details.
[3]:
s.remove_static_background()
s.remove_dynamic_background()
Note
DI is computationally intensive and takes in general a long time to run due to all the pattern comparisons being done. To maintain an acceptable memory usage and be done within reasonable time, it is recommended to write processed patterns to an HDF5 file for quick reading during DI.
[4]:
# s.save("pattern_static_dynamic.h5")
Dictionary indexing#
Load a master pattern#
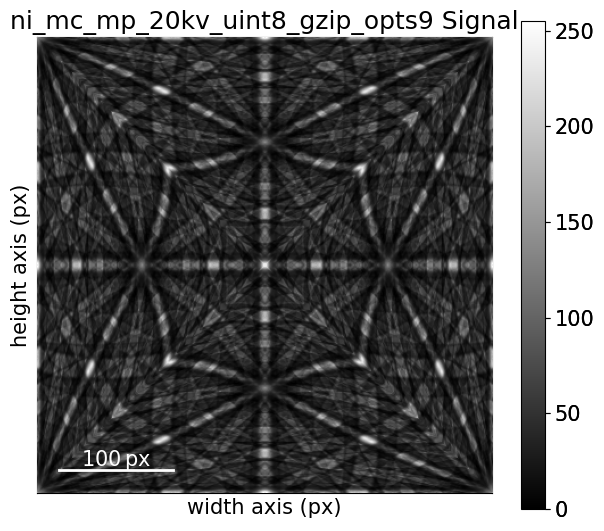
Next, we load a dynamically simulated nickel master pattern for an accelerating voltage of 20 keV, generated with EMsoft. The master pattern is in the upper hemisphere projection of the square Lambert projection.
[5]:
energy = 20
mp = kp.data.nickel_ebsd_master_pattern_small(
projection="lambert", energy=energy
)
mp
[5]:
<EBSDMasterPattern, title: ni_mc_mp_20kv_uint8_gzip_opts9, dimensions: (|401, 401)>
[6]:
mp.plot()
The nickel phase information, specifically the crystal symmetry, asymmetric atom positions, and crystal lattice, is conveniently stored in an orix.crystal_map.Phase
<name: ni. space group: Fm-3m. point group: m-3m. proper point group: 432. color: tab:blue>
lattice=Lattice(a=0.35236, b=0.35236, c=0.35236, alpha=90, beta=90, gamma=90)
28 0.000000 0.000000 0.000000 1.0000
Sample orientation space#
If we don’t know anything about the possible crystal orientations in our sample, the safest thing to do is to generate a dictionary of orientations uniformly distributed in a candidate phase’s orientation space. To achieve this, we sample the Rodrigues Fundamental Zone (RFZ) of the proper point group 432 using cubochoric sampling [Singh and De Graef, 2016] available in orix.sampling.get_sample_fundamental(). We can choose the average disorientation between orientations, the “resolution”, of this sampling. Here, we will use a rather low resolution of 3\(^{\circ}\).
[8]:
R = sampling.get_sample_fundamental(
method="cubochoric", resolution=3, point_group=ni.point_group
)
R
[8]:
Rotation (30443,)
[[ 0.8562 -0.3474 -0.3474 -0.1595]
[ 0.8562 -0.3511 -0.3511 -0.1425]
[ 0.8562 -0.3544 -0.3544 -0.1252]
...
[ 0.8562 0.3544 0.3544 0.1252]
[ 0.8562 0.3511 0.3511 0.1425]
[ 0.8562 0.3474 0.3474 0.1595]]
This sampling resulted in about 30 000 crystal orientations. See the orix documentation on orientation sampling for further details and options for orientation sampling.
Note
An average disorientation of 3\(^{\circ}\) results in a course sampling of orientation space; a lower average disorientation should be used for experimental work.
Define the detector-sample geometry#
Now that we have our master pattern and crystal orientations, we need to describe the EBSD detector’s position with respect to the sample (interaction volume). This ensures that projecting parts of the master pattern onto our detector yields dynamically simulated patterns resembling our experimental ones. See the reference frames tutorial and the EBSDDetector class for further details.
[9]:
det = kp.detectors.EBSDDetector(
shape=s.axes_manager.signal_shape[::-1],
pc=[0.4198, 0.2136, 0.5015],
sample_tilt=70,
)
det
[9]:
EBSDDetector
shape (Ny, Nx): (60, 60)
pc (PCx, PCy, PCz): (0.42, 0.214, 0.501)
sample_tilt: 70.0°
tilt: 0.0°
azimuthal: 0.0°
twist: 0.0°
binning: 1
px_size: 1.0 um
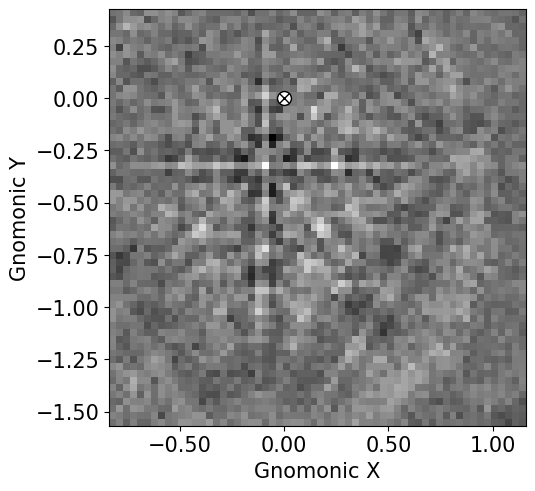
Let’s double check the projection/pattern center (PC) position on the detector using plot()
[10]:
det.plot(coordinates="gnomonic", pattern=s.inav[0, 0].data)
Generate dictionary#
Now we’re ready to generate our dictionary of simulated patterns. We do so by projecting parts of the master pattern onto our detector for all sampled orientations using the get_patterns() method. The method assumes the crystal orientations are defined with respect to the EDAX TSL sample reference frame RD-TD-ND.
Note
It is in general adviced to not compute the dictionary immediately, but let the dictionary indexing method handle this, by passing compute=False. This will return a LazyEBSD signal, with the dictionary patterns as a Dask array.
Tip: If compute=False, it is recommended to control the number of patterns in each chunk by passing chunk_shape=1000 if we want 1 000 patterns per chunk. Alternatively, chunk_shape=rot.size // 30 gives 30-31 chunks. If we at the same time do not pass n_per_iteration to dictionary_indexing(), our here specified chunk size will be the number of simulated patterns matched per iteration, which should give a faster and less memory intensive indexing!
[11]:
sim = mp.get_patterns(
rotations=R,
detector=det,
energy=energy,
dtype_out=np.float32,
compute=True,
)
sim
[########################################] | 100% Completed | 840.13 ms
[11]:
<EBSD, title: , dimensions: (30443|60, 60)>
Let’s inspect the three first of the simulated patterns
[12]:
# sim.plot() # Plot the patterns with a navigator for easy inspection
fig, ax = plt.subplots(ncols=3, figsize=(18, 6))
for i in range(3):
ax[i].imshow(sim.inav[i].data, cmap="gray")
euler = sim.xmap[i].rotations.to_euler(degrees=True)[0]
ax[i].set_title(
rf"$(\phi_1, \Phi, \phi_2)$ = {np.array_str(euler, precision=1)}"
)
ax[i].axis("off")
fig.subplots_adjust(wspace=0.05)

Perform indexing#
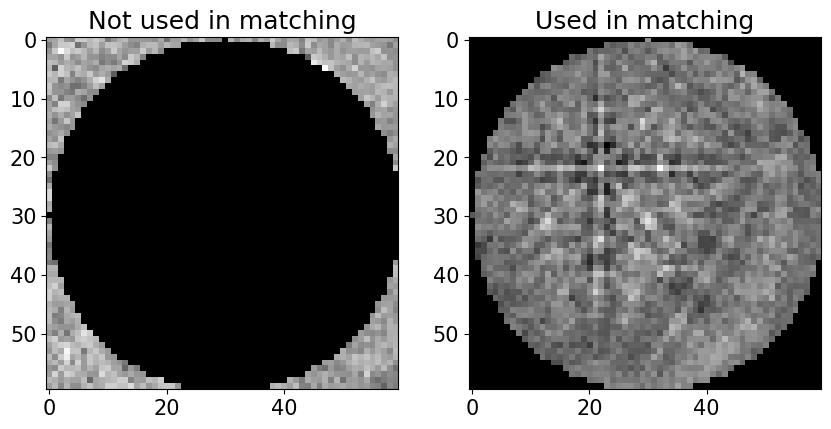
The Kikuchi pattern signal is often weak towards the corners of the detector. In such cases, we can pass a signal mask to exclude the pixels where the mask values are True. This convention is in line with how NumPy, Dask, scikit-image etc. defines a mask. The mask can take whatever shape we want, as long as it is a boolean array of the detector shape.
[13]:
signal_mask = ~kp.filters.Window("circular", det.shape).astype(bool)
p = s.inav[0, 0].data
fig, ax = plt.subplots(ncols=2, figsize=(10, 5))
ax[0].imshow(p * signal_mask, cmap="gray")
ax[0].set_title("Not used in matching")
ax[1].imshow(p * ~signal_mask, cmap="gray")
_ = ax[1].set_title("Used in matching");
Finally, let’s use the dictionary_indexing() method to match the simulated patterns to our experimental patterns. We use the zero-mean normalized cross correlation (NCC) coefficient \(r\) [Gonzalez and Woods, 2017] as our similarity metric (it is the default). Let’s keep the 20 best matching orientations. A number of 4125 * 30 443 comparisons is quite small, which we can do in memory all at once. In cases where the number of comparisons is too big for our memory to handle, we should iterate over the dictionary of simulated patterns by passing the number of patterns per iteration. To demonstrate this, we do at least 10 iterations here. The results are returned as a orix.crystal_map.CrystalMap.
[14]:
Dictionary indexing information:
Phase name: ni
Matching 4125 experimental pattern(s) to 30443 dictionary pattern(s)
NormalizedCrossCorrelationMetric: float32, greater is better, rechunk: False, navigation mask: False, signal mask: True
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11/11 [00:02<00:00, 3.88it/s]
Indexing speed: 1454.83606 patterns/s, 44289574.17808 comparisons/s
[14]:
Phase Orientations Name Space group Point group Proper point group Color
0 4125 (100.0%) ni Fm-3m m-3m 432 tab:blue
Properties: scores, simulation_indices
Scan unit: um
Note
Dictionary indexing of real world data sets takes a long time because the matching is computationally intensive. The dictionary_indexing() method accepts parameters n_per_iteration, rechunk, and dtype that lets us control this behaviour to a certain extent. Be sure to take a look at the method’s docstring for further details.
Check the average of the best matching score per pattern
[15]:
print(xmap.scores[:, 0].mean())
0.32273704
The normalized dot product can be used instead of the NCC by passing metric="ndp". A custom metric can be used instead, by creating a class which inherits from the abstract class SimilarityMetric.
The results can be exported to an HDF5 file re-readable by orix, or an .ang file readable by MTEX and some commercial packages
[16]:
temp_dir = tempfile.mkdtemp() + "/"
io.save(temp_dir + "ni.h5", xmap)
io.save(temp_dir + "ni.ang", xmap)
Validate indexing results#
With the orix library we can plot inverse pole figures (IPFs), color crystal directions to produce inverse pole figure (IPF) maps, and more. This is useful for quick validation of our results before quantitative orientation analysis. At the moment, if we want to analyze the results in terms of reconstructed grains, textures from orientation density functions, or similar, we have to use other software, such as MTEX or DREAM.3D.
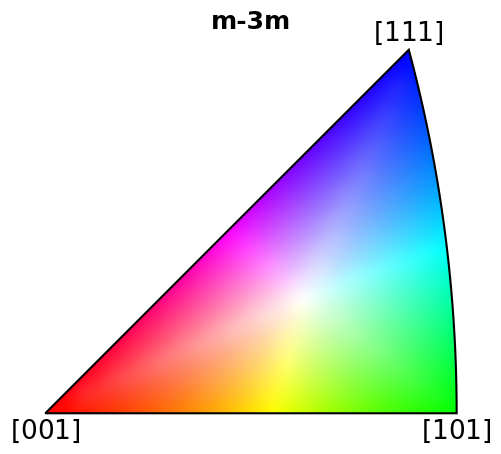
Let’s generate an IPF color key and plot it
[17]:
pg = ni.point_group
ckey_m3m = plot.IPFColorKeyTSL(pg, direction=Vector3d.xvector())
print(ckey_m3m)
ckey_m3m.plot()
IPFColorKeyTSL, symmetry: m-3m, direction: [1 0 0]
With this color key, we can color orientations according to which crystal directions the sample direction \(X\) points in in every map pixel (overlaying the NCC scores of the best match)
[18]:

With a few more lines, we can plot IPF maps for X, Y, and Z
[19]:
Or = xmap.orientations
v_sample = Vector3d(((1, 0, 0), (0, 1, 0), (0, 0, 1)))
fig, axes = plt.subplots(figsize=(15, 5), ncols=3)
for ax, v, title in zip(axes, v_sample, ("X", "Y", "Z")):
ckey_m3m.direction = v
rgb = ckey_m3m.orientation2color(Or).reshape(xmap.shape + (3,))
ax.imshow(rgb)
ax.axis("off")
ax.set(title=f"IPF-{title}")
fig.subplots_adjust(wspace=0.05)

The sample is recrystallized nickel, so we expect a continuous color within grains, except for twinning grains. The orientation maps are mostly in line with our expectation. Some grains have a scatter of similar colors, which is most likely due to the discrete nature of our dictionary. To improve upon this result we can reduce the orientation sampling characteristic distance. This will increase our dictionary size and thus our indexing time. An alternative is to perform orientation refinement, which we will do below.
We can get further confirmation of our initial analysis by inspecting some indexing quality maps, like the best matching scores and so-called orientation similarity (OS) map, which compares the best matching orientations for each pattern to it’s nearest neighbours. Let’s get the NCC map in the correct shape from the CrystalMap’s scores property and the OS map with orientation_similarity_map() using the full list of best matches per point
[20]:
ncc_map = xmap.scores[:, 0].reshape(*xmap.shape)
os_map = kp.indexing.orientation_similarity_map(xmap)
And plot the maps
[21]:
fig, axes = plt.subplots(ncols=2, figsize=(11, 3))
im0 = axes[0].imshow(ncc_map)
im1 = axes[1].imshow(os_map)
fig.colorbar(im0, ax=axes[0], label="NCC", pad=0.02)
fig.colorbar(im1, ax=axes[1], label="Orientation similarity", pad=0.02)
for ax in axes:
ax.axis("off")
fig.subplots_adjust(wspace=0)
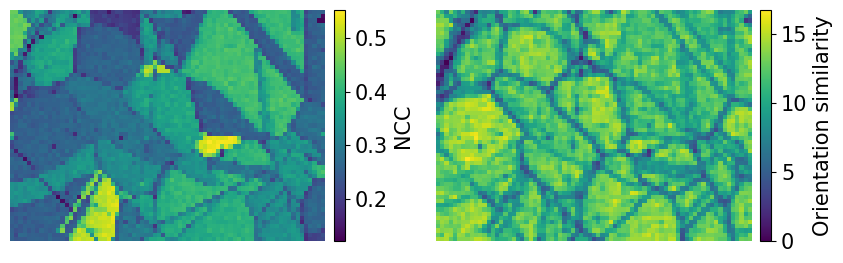
From the NCC map we see that some grains match better than others. Due to the discrete nature of our dictionary, it is safe to assume that the best matching grains have patterns more similar to those in the dictionary than the others, i.e. the different coefficients does not reflect anything physical in the microstructure. The OS map doesn’t tell us much more than the NCC map in this case.
We can use the crystal map property simulation_indices to get the best matching simulated patterns from the dictionary of simulated patterns
[22]:
best_patterns = sim.data[xmap.simulation_indices[:, 0]].reshape(s.data.shape)
s_best = kp.signals.EBSD(best_patterns)
s_best
[22]:
<EBSD, title: , dimensions: (75, 55|60, 60)>
The simplest way to visually compare the experimental and best matching simulated patterns is to plot them with the same navigator. Let’s create an RGB navigator signal from the IPF-X orientation map with get_rgb_navigator(). When using an interactive backend like Qt5Agg, we can then move the red square around to look at the patterns in each point.
[23]:
rgb_navigator = kp.draw.get_rgb_navigator(rgb_x.reshape(xmap.shape + (3,)))
hs.plot.plot_signals([s, s_best], navigator=rgb_navigator)
Let’s also plot the best matches for patterns from two grains
[24]:
grain1 = (0, 0)
grain2 = (30, 10)
fig, axes = plt.subplots(ncols=2, nrows=2, figsize=(8, 8))
axes[0, 0].imshow(s.inav[grain1].data, cmap="gray")
axes[0, 1].imshow(s_best.inav[grain1].data, cmap="gray")
axes[1, 0].imshow(s.inav[grain2].data, cmap="gray")
axes[1, 1].imshow(s_best.inav[grain2].data, cmap="gray")
for ax in axes.ravel():
ax.axis("off")
fig.subplots_adjust(wspace=0.01, hspace=0.01)

Refinement#
Let’s look at the effect of three refinement routes, all implemented as EBSD methods:
Refine orientations while keeping the PCs fixed: refine_orientation()
Refine PCs while keeping the orientations fixed: refine_projection_center()
Refine orientations and PCs at the same time: refine_orientation_projection_center()
For each route we will compare the maps and histograms of NCC scores before and after refinement, and also the PC parameters if appropriate.
Optimization is performed using an algorithm from the SciPy library or the NLopt library. Note that NLopt is an optional dependency (see the installation guide for details). For every orientation and/or PC, we want to iteratively increase the similarity (NCC score) between our experimental pattern and a new simulated pattern projected onto our EBSD detector for every iteration, until the increase in similarity (gain) from one iteration to the next is smaller a certain threshold, by default 0.0001 for most algorithms. The orientation and/or PC is changed slightly in a controlled manner by the optimization algorithm for every iteration. The number of optimization evaluations (iterations) is returned after each refinement, either as a property in the crystal map (in route 1. and 3.) or as an array (in route 2.). We have access to both local and global optimization algorithms. Consult the kikuchipy docstring methods and the documentation of SciPy and NLopt, all linked above, for all available parameters and options.
Note that while we here refine orientations obtained from DI, any orientation results, e.g. from Hough indexing, can be refined with this approach, as long as an appropriate master pattern, EBSDDetector with PCs and a CrystalMap with orientations are provided.
Note
When using the Nelder-Mead optimization algorithm, EBSD refinement is generally faster with NLopt than with SciPy. Therefore, it is recommended to use NLopt. NLopt is however not as available on various machine architectures and across Python versions as SciPy is. This is why NLopt is an optional dependency and why SciPy’s Nelder-Mead algorithm is the default in all refinement methods.
Refine orientations#
We use refine_orientation() to refine orientations while keeping the PCs fixed, using the default local Nelder-Mead simplex method from SciPy
[25]:
Refinement information:
Method: Nelder-Mead (local) from SciPy
Trust region (+/-): None
Keyword arguments passed to method: {'method': 'Nelder-Mead', 'tol': 0.0001}
Refining 4125 orientation(s):
[########################################] | 100% Completed | 12.39 ss
Refinement speed: 332.74292 patterns/s
Check the mean of the best matching score per pattern and the average number of optimization evaluations (iterations)
0.4839914150382533
93.78278787878787
Compare the NCC score maps. We use the same colorbar bounds for both maps
[27]:
[28]:
ncc_after_ori_ref_label = "NCC after ori. ref."
fig, axes = plt.subplots(ncols=2, figsize=(11, 3))
im0 = axes[0].imshow(ncc_map, vmin=vmin, vmax=vmax)
im1 = axes[1].imshow(ncc_after_ori_ref, vmin=vmin, vmax=vmax)
fig.colorbar(im0, ax=axes[0], label="NCC from DI", pad=0.02)
fig.colorbar(im1, ax=axes[1], label=ncc_after_ori_ref_label, pad=0.02)
for ax in axes:
ax.axis("off")
fig.subplots_adjust(wspace=0)
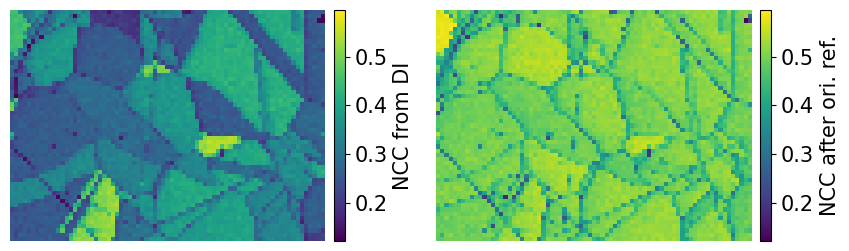
Compare the histograms
[29]:
bins = np.linspace(vmin, vmax, 100)
fig, ax = plt.subplots(figsize=(9, 5))
_ = ax.hist(ncc_map.ravel(), bins, alpha=0.5, label="NCC from DI")
_ = ax.hist(
ncc_after_ori_ref.ravel(),
bins,
alpha=0.5,
label=ncc_after_ori_ref_label,
)
ax.set(
xlabel="Normalized cross correlation (NCC) scores", ylabel="Frequency"
)
ax.legend()
fig.tight_layout();
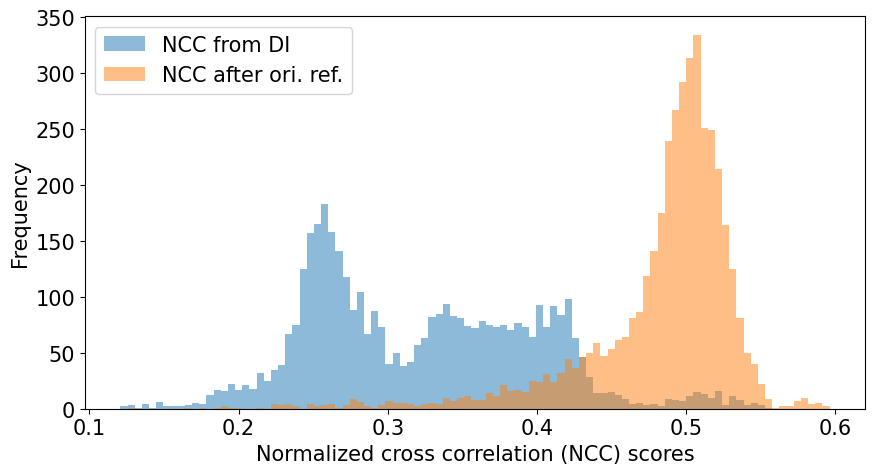
We see that DI found the best orientation (with a fixed PC) for most of the patterns, which the refinement was able to improve further. However, there are a few patterns with a very low NCC score (0.1-0.2) which refinement couldn’t improve upon, which tells us that these were most likely misindexed during DI. If there are Kikuchi bands in these patterns, a larger dictionary with a finer orientation sampling could improve indexing of them.
Let’s also plot the IPF-X orientation maps before and after refinement, and also the disorientation angle (smallest misorientation angle found after accounting for symmetry) difference between the two maps
[30]:
O_ref = xmap_ref.orientations
ckey_m3m.direction = Vector3d.xvector()
rgb_x = ckey_m3m.orientation2color(Or)
rgb_x_ref = ckey_m3m.orientation2color(O_ref)
angles = Or.angle_with(O_ref, degrees=True)
fig, axes = plt.subplots(ncols=3, figsize=(14, 3))
axes[0].imshow(rgb_x.reshape(xmap.shape + (3,)))
axes[1].imshow(rgb_x_ref.reshape(xmap.shape + (3,)))
im2 = axes[2].imshow(angles.reshape(xmap.shape))
fig.colorbar(
im2, ax=axes[2], label=r"Misorientation angle $\omega$ [$^{\circ}$]"
)
for ax in axes:
ax.axis("off")
fig.tight_layout(w_pad=-12)

We see that refinement was able to remove the scatter of similar colors in the grains.
Finally, let’s plot the IPF-X map with correlation scores overlayed. We will also plot the IPF color key in the bottom right corner.
[31]:
fig = xmap_ref.plot(
rgb_x_ref, overlay="scores", remove_padding=True, return_figure=True
)
# Place color key in bottom right corner,
# coordinates are [left, bottom, width, height]
ax_ckey = fig.add_axes([0.75, 0.08, 0.2, 0.2], projection="ipf", symmetry=pg)
ax_ckey.plot_ipf_color_key(show_title=False)
ax_ckey.patch.set_facecolor("None")
_ = [text.set_color("w") for text in ax_ckey.texts] # White [uvw]
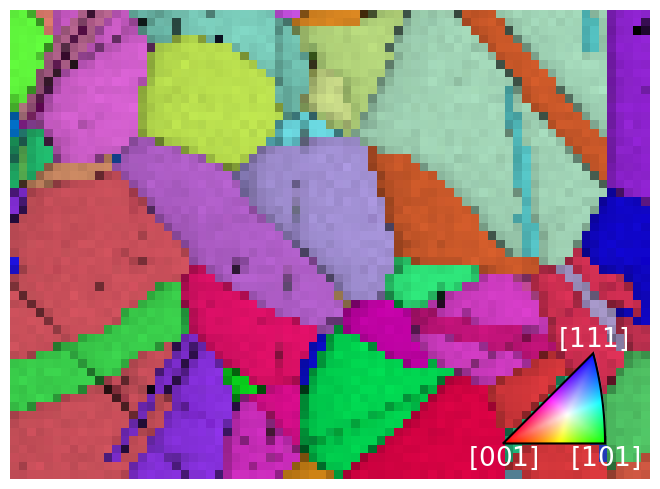
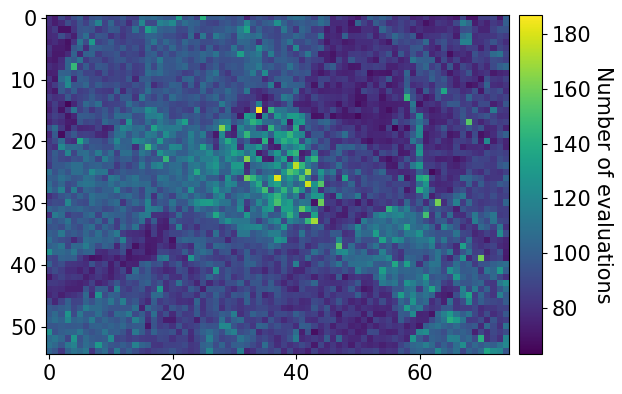
Finally, let’s plot the number of optimization evaluations (iterations) necessary for each pattern
[32]:
xmap_ref.plot(
"num_evals", colorbar=True, colorbar_label="Number of evaluations"
)
Refine projection centers#
We use refine_projection_center() to refine PCs while keeping the orientations fixed. We’ll demonstrate this using the local modified Powell method from SciPy. This method is also known as Bound Optimization BY Quadratic Approximation (BOBYQA), and is used in EMsoft and discussed by [Singh et al., 2017]. We will pass a trust_region of +/- 2% for the PC parameters to use as upper and lower bounds during
refinement.
We can also pass compute=False, to do the refinement later. The results will then be a dask.array.Array. We can pass this array to kikuchipy.indexing.compute_refine_projection_center_results() and perform the refinement to retrieve the results
[33]:
Refinement information:
Method: Powell (local) from SciPy
Trust region (+/-): [0.02 0.02 0.02]
Keyword arguments passed to method: {'method': 'Powell', 'tol': 0.001}
[34]:
(
ncc_after_pc_ref,
det_ref,
num_evals_ref,
) = kp.indexing.compute_refine_projection_center_results(
results=result_arr, detector=det, xmap=xmap
)
Refining 4125 projection center(s):
[########################################] | 100% Completed | 11.00 ss
Refinement speed: 374.63330 patterns/s
Check the mean of the best matching score per pattern and the average number of optimization evaluations (iterations)
0.4006852817101912
65.60193939393939
Note that refine_orientation() and refine_orientation_projection_center() also takes the compute parameter, and there are similar functions to compute the refinement results: kikuchipy.indexing.compute_refine_orientation_results() and
kikuchipy.indexing.compute_refine_orientation_projection_center_results().
Let’s plot the refined scores and PCs
[36]:
[37]:
ncc_after_pc_ref_label = "NCC after PC refinement"
fig, axes = plt.subplots(ncols=2, figsize=(11, 3))
im0 = axes[0].imshow(ncc_map, vmin=vmin2, vmax=vmax2)
im1 = axes[1].imshow(ncc_after_pc_ref, vmin=vmin2, vmax=vmax2)
fig.colorbar(im0, ax=axes[0], label="NCC from DI", pad=0.02)
fig.colorbar(im1, ax=axes[1], label=ncc_after_pc_ref_label, pad=0.02)
for ax in axes:
ax.axis("off")
fig.tight_layout(w_pad=-7)
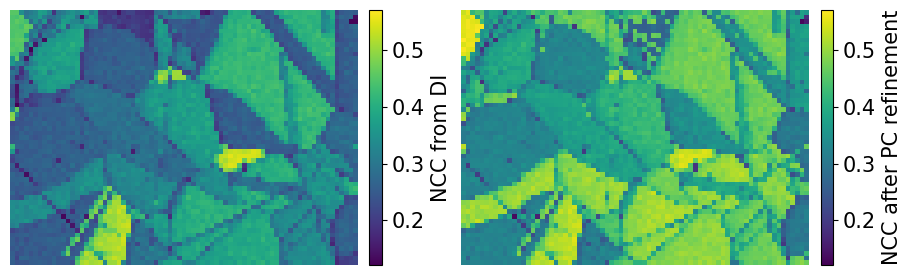
Compare the NCC score histograms
[38]:
bins = np.linspace(vmin2, vmax2, 100)
fig, ax = plt.subplots(figsize=(9, 5))
_ = ax.hist(ncc_map.ravel(), bins, alpha=0.5, label="NCC from DI")
_ = ax.hist(
ncc_after_pc_ref.ravel(),
bins,
alpha=0.5,
label=ncc_after_pc_ref_label,
)
ax.set(
xlabel="Normalized cross correlation (NCC) scores", ylabel="Frequency"
)
ax.legend()
fig.tight_layout();
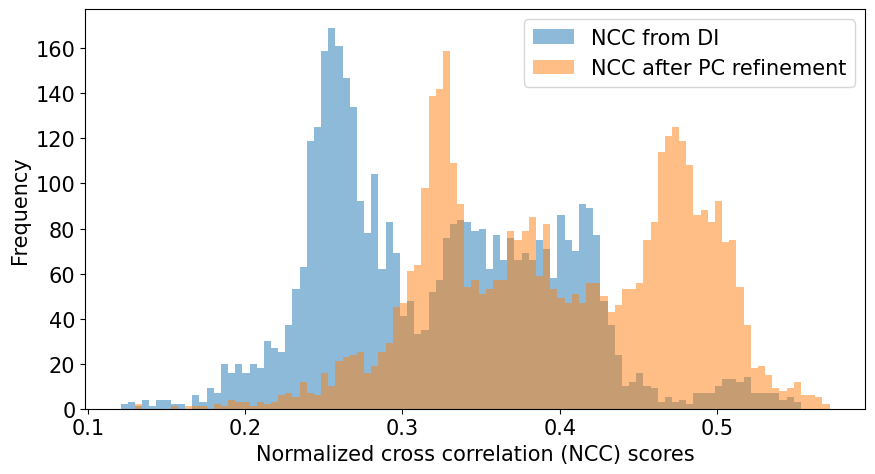
[39]:
print(
f"PC used in DI: {det.pc_average}\n"
f"PC after PC refinement: {det_ref.pc_average.round(4)}"
)
det_ref.plot_pc()
PC used in DI: [0.4198 0.2136 0.5015]
PC after PC refinement: [0.4188 0.215 0.5023]
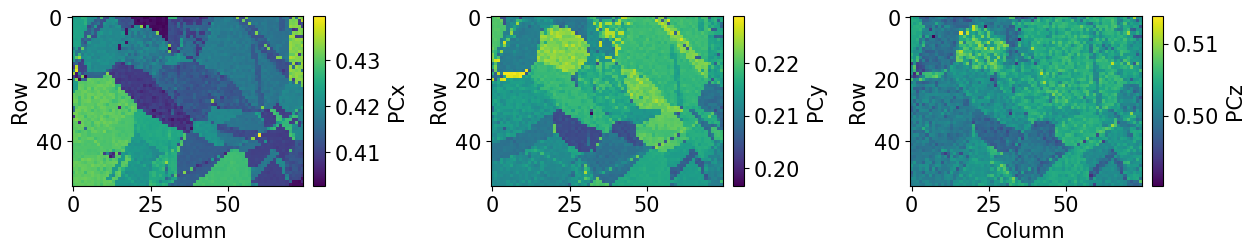
The maps indicate an orientation dependence of the PC, meaning that changes in PC can be accomodated by crystal rotations, to a certain extent. We can plot the PCs as functions of each other and color them according to the IPF-X map above to see this more clearly
[40]:
det_ref.plot_pc("scatter", c=rgb_x, alpha=0.2)
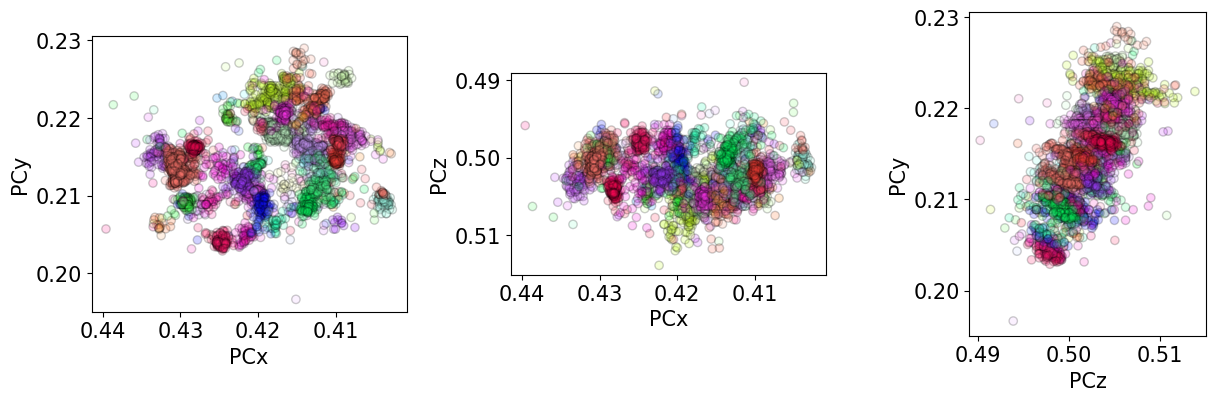
This orientation dependent “slop” is nicely demonstrated by [Pang et al., 2020]. A part of their analysis is shown in the Orientation dependence of the projection center tutorial.
Refine orientations and projection centers#
We use refine_orientation_projection_center() to refine orientations and PCs at the same time. To do this we’ll use the implementation of Nelder-Mead in NLopt, an optional dependency (see the installation guide for details).
[41]:
Refinement information:
Method: LN_NELDERMEAD (local) from NLopt
Trust region (+/-): [2. 2. 2. 0.05 0.05 0.05]
Relative tolerance: 0.001
Refining 4125 orientation(s) and projection center(s):
[########################################] | 100% Completed | 17.61 ss
Refinement speed: 234.13019 patterns/s
Check the mean of the best matching score per pattern and the average number of optimization evaluations (iterations)
0.47938314375371643
116.52266666666667
Compare the NCC score maps. We use the same colorbar bounds for both maps
[43]:
[44]:
ncc_after_ori_pc_ref_label = "NCC after ori./PC ref."
fig, axes = plt.subplots(ncols=2, figsize=(11, 3))
im0 = axes[0].imshow(ncc_map, vmin=vmin3, vmax=vmax3)
im1 = axes[1].imshow(ncc_after_ori_pc_ref, vmin=vmin3, vmax=vmax3)
fig.colorbar(im0, ax=axes[0], label="NCC from DI", pad=0.02)
fig.colorbar(im1, ax=axes[1], label=ncc_after_ori_pc_ref_label, pad=0.02)
for ax in axes:
ax.axis("off")
fig.subplots_adjust(wspace=0)
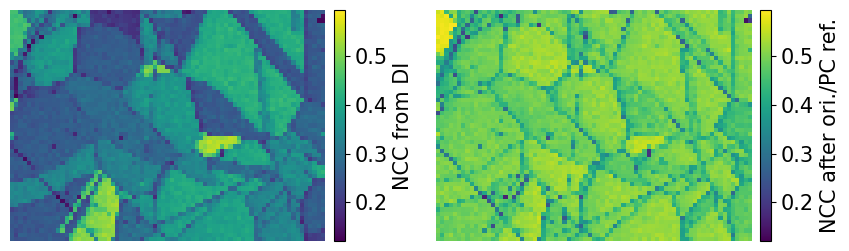
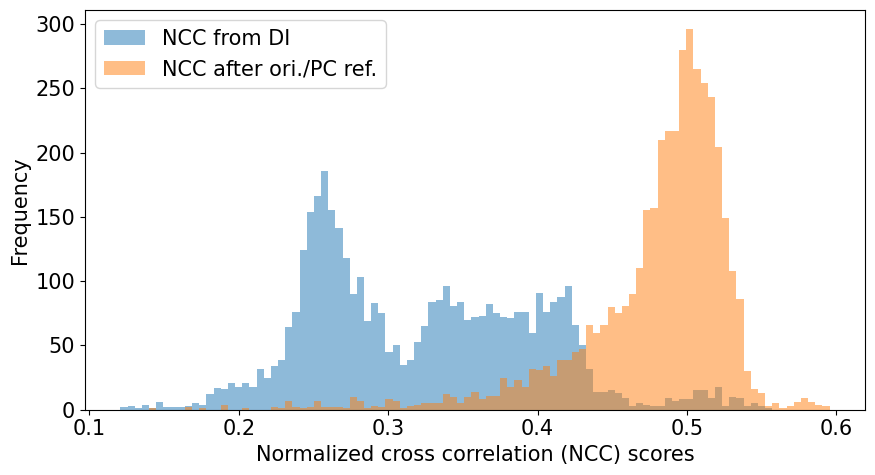
Compare the histograms
[45]:
bins = np.linspace(vmin3, vmax3, 100)
fig, ax = plt.subplots(figsize=(9, 5))
_ = ax.hist(ncc_map.ravel(), bins, alpha=0.5, label="NCC from DI")
_ = ax.hist(
ncc_after_ori_pc_ref.ravel(),
bins,
alpha=0.5,
label=ncc_after_ori_pc_ref_label,
)
ax.set(
xlabel="Normalized cross correlation (NCC) scores", ylabel="Frequency"
)
ax.legend()
fig.tight_layout();
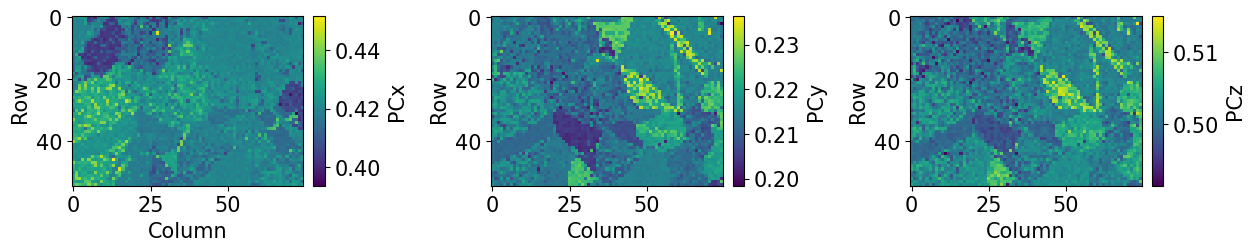
Let’s also inspect the refined PC parameters
[46]:
print(
f"PC used in DI: {det.pc_average}\n"
f"PC after PC refinement: {det_ref2.pc_average.round(4)}"
)
det_ref2.plot_pc()
PC used in DI: [0.4198 0.2136 0.5015]
PC after PC refinement: [0.4204 0.2148 0.5022]
[47]:
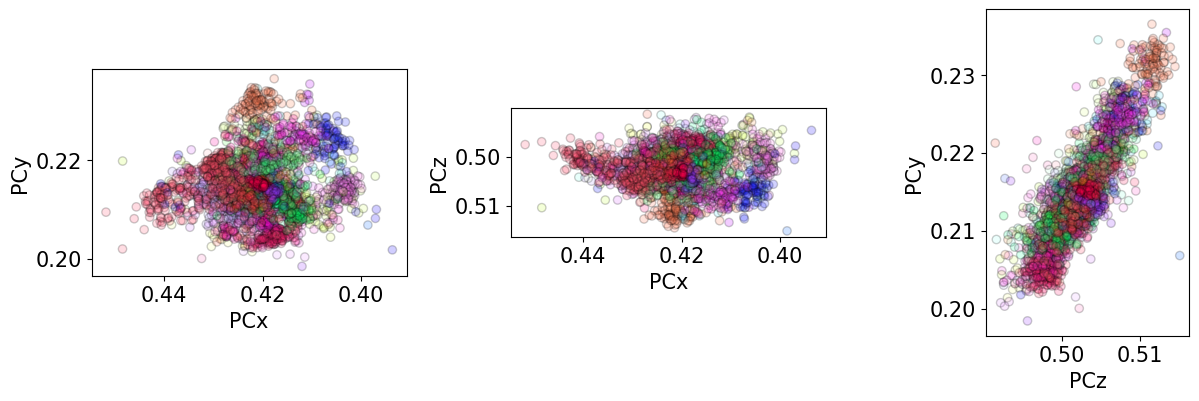
We see that the ranges of refined PCs have narrowed compared to when only the PC was optimized (as seen above). But, the unexpected inverse relation between PCz and PCy remains.
It is generally advisable to refine orientations and PCs simultaneously only when estimating PCs in a grid across the sample in order to fit a plane of PCs to this grid. Indexing can then be performed with a PC from this plane for each pattern, only refining the orientation.