

Live notebook
You can run this notebook in a live session ![]() or view it on Github.
or view it on Github.
Orientation-dependence of the projection center#
In this tutorial, we will see that the error in the projection center (PC) estimated from pattern matching can be orientation-dependent. When finding an average PC to use for indexing, it is therefore important to average PCs from not only many patterns, but from many patterns from different grains as well, if possible.
The orientation-dependence of the PC error is nicely demonstrated by [Pang et al., 2020]. They simulateneously optimize the orientation and PCs of experimental nickel patterns from an openly available dataset, released by [Jackson et al., 2019]. To test their optimization routine, they compare optimized PCs to those expected from geometrical considerations.
When the dataset was acquired, the sample was tilted \(\sigma = 75.7^{\circ}\) towards the detector, while the detector was tilted \(\theta = 10^{\circ}\) away from the sample. These tilts give a combined \(\alpha = 90^{\circ} - \sigma + \theta\) tilt about the detector \(X_d\) axis, which brings the sample normal parallel to the detector normal. A scan of (n rows, m columns) = (151, 181) patterns with a nominal step size of 1.5 μm was acquired in a nominally regular grid on the sample. The sample \(y\)-direction increases “up the sample”. Given these geometrical considerations, the PC is expected to change following the following equations:
\begin{align} \frac{PC_x}{\Delta y} &= 1,\\ \frac{PC_y}{\Delta y} &= \cos{\alpha} \cdot \frac{1}{\delta},\\ \frac{PC_z}{\Delta y} &= \sin{\alpha}. \end{align}
Here, Bruker’s PC convention is used (see the reference frame tutorial). \(\delta\) is the detector pixel size. The detector used in this experiment has a pixel size of \(\delta = 59.2\) μm.
Pang and co-workers optimize the orientation solutions and PCs saved with the experimental data as determined from Hough indexing with EDAX OIM. In this tutorial, we do the following:
Obtain a good starting PC for the refinement:
Optimize the PC of 49 patterns extracted in a grid from the full dataset using Hough indexing. We will use the EDAX OIM PC as the initial guess.
Index the grid patterns using Hough indexing.
Refine the orientations and PCs using pattern matching.
Calculate an average PC using the reliably refined PCs.
Index all (151, 181) patterns using Hough indexing with the average PC.
Refine Hough indexed orientations and average PC using pattern matching. This is only be done for a vertical slice of the full dataset (the same slice used by Pang and co-workers). The slice has shape (151, 10).
To validate our results, we average the refined PCs along the horizontal (giving one PC per 151 vertical position) and compare them to the ones expected from the equations above.
Pang and co-workers use the global optimization algorithm SNOBFIT to optimize orientations and PCs simultaneously. Here, we will use the local optimization algorithm Nelder-Mead, as implemented in NLopt, and see that we obtain comparable results.
Note
To run this tutorial, the experimental nickel patterns must be downloaded from the supplementary material to [Jackson et al., 2019].
Additionally, a high resolution [typically of (1001, 1001) pixels] nickel EBSD master pattern in the (square) Lambert projection is required. This can be simulated with e.g. EMsoft. Or, it can be downloaded via the kikuchipy.data module.
Let’s import necessary libraries
[1]:
# Exchange inline for notebook or qt5 (from pyqt) for interactive plotting
%matplotlib inline
import matplotlib.patches as mpatches
import matplotlib.pyplot as plt
import numpy as np
from scipy.optimize import curve_fit
from diffsims.crystallography import ReciprocalLatticeVector
import hyperspy.api as hs
import kikuchipy as kp
from orix import plot
from orix.crystal_map import PhaseList
plt.rcParams.update(
{
"figure.facecolor": "w",
"figure.dpi": 75,
"figure.figsize": (8, 8),
"font.size": 15,
}
)
Load and inspect data#
Load (lazily) the experimental nickel data from [Jackson et al., 2019]
[2]:
s = kp.load("../../../../../data/ebsd/formater/edax/EDAX-Ni.h5", lazy=True)
s
[2]:
|
|
These are already static background corrected. But here, we remove the dynamic background (lazily) as well
[3]:
s.remove_dynamic_background()
Load the Ni EBSD master pattern simulated with EMsoft (upper hemisphere only)
[4]:
mp = kp.data.ebsd_master_pattern(
"ni", allow_download=True, projection="lambert", energy=20
)
mp
[4]:
<EBSDMasterPattern, title: ni_mc_mp_20kv, dimensions: (|1001, 1001)>
[5]:
mp.plot(navigator=None)

Extract the phase and change the lattice parameters from nm to Ångström
[6]:
<name: ni. space group: Fm-3m. point group: m-3m. proper point group: 432. color: tab:blue>
lattice=Lattice(a=3.5236, b=3.5236, c=3.5236, alpha=90, beta=90, gamma=90)
28 0.000000 0.000000 0.000000 1.0000
/var/folders/pw/922n1x9d1_941f372c96y5t00000gn/T/ipykernel_4236/2835719919.py:3: DeprecationWarning: 'diffpy.structure.Lattice.setLatPar' is deprecated and will be removed in version 4.0.0. Please use 'diffpy.structure.Lattice.set_latt_parms' instead.
lat.setLatPar(lat.a * 10, lat.b * 10, lat.c * 10)
Extract a (4, 4) grid of patterns using EBSD.extract_grid()
[7]:
grid_shape = (4, 4)
s_grid, idx = s.extract_grid(grid_shape, return_indices=True)
s_grid.compute()
s_grid
[7]:
<EBSD, title: EDAX-Ni Scan 1, dimensions: (4, 4|60, 60)>
Inspect an image quality map (we have to compute the returned Dask array since we loaded data lazily above)
[8]:
iq = s.get_image_quality()
iq = iq.compute()
Plot the positions of the extracted patterns on the grid
[9]:
# For convenience, use the plot method of the crystal map attached to the EBSD
# signal to plot the IQ map. The array must be 1D.
s.xmap.scan_unit = "um"
fig = s.xmap.plot(
iq.ravel(),
vmax=0.3,
remove_padding=True,
colorbar=True,
colorbar_label="IQ",
return_figure=True,
)
kp.draw.plot_pattern_positions_in_map(
rc=idx.reshape(2, -1).T,
roi_shape=s.xmap.shape,
axis=fig.axes[0],
color="w",
)

Plot the grid patterns, using a radial mask to remove intensities without Kikuchi diffraction
[10]:
signal_mask = kp.filters.Window("circular", s_grid.detector.shape)
signal_mask = ~signal_mask.astype(bool)
fig = plt.figure(figsize=(9.5, 9.5))
_ = hs.plot.plot_images(
s_grid * ~signal_mask,
fig=fig,
axes_decor=None,
label=None,
colorbar=False,
per_row=grid_shape[0],
padding=dict(wspace=0.03, hspace=0.03),
tight_layout=True,
)
for i, ax in enumerate(fig.axes):
ax.text(1, 1, i, va="top", ha="left", c="w")
ax.axis("off")

Estimate average PC from grid of patterns#
We estimate an average PC and do Hough indexing of the grid patterns using PyEBSDIndex. See the Hough indexing tutorial for more details on the Hough indexing-related commands below.
Note
PyEBSDIndex is an optional dependency of kikuchipy, and can be installed with both pip and conda (from conda-forge). To install PyEBSDIndex, see their installation instructions.
We use relevant sample-detector geometry values read from the EDAX file, stored in the kikuchipy.signals.EBSD.detector attribute. Note that the PC is in the Bruker convention (used internally); see the reference frames tutorial for details.
[11]:
det = s_grid.detector
det
[11]:
EBSDDetector
shape (Ny, Nx): (60, 60)
pc (PCx, PCy, PCz): (0.507, 0.262, 0.558)
sample_tilt: 75.7°
tilt: 10.0°
azimuthal: 0.0°
twist: 0.0°
binning: 1
px_size: 1.0 um
We need an EBSDIndexer to use PyEBSDIndex. We can obtain an indexer by passing a PhaseList to EBSDDetector.get_indexer()
[12]:
Id Name Space group Point group Proper point group Color
0 ni Fm-3m m-3m 432 tab:blue
[13]:
indexer = det.get_indexer(
pl,
reflectors=[[1, 1, 1], [2, 0, 0], [2, 2, 0], [3, 1, 1]],
rSigma=2,
tSigma=2,
)
Estimate the PC for the grid patterns using particle swarm optimization (PSO), also printing the mean and standard deviation
[14]:
PC found: [********* ] 16/16 global best:0.269 PC opt:[0.5073 0.2621 0.5585]
[0.50766556 0.27395053 0.5559635 ]
[0.0112807 0.01566688 0.01580073]
Plot the PCs
[15]:
det_grid.plot_pc("scatter", annotate=True)
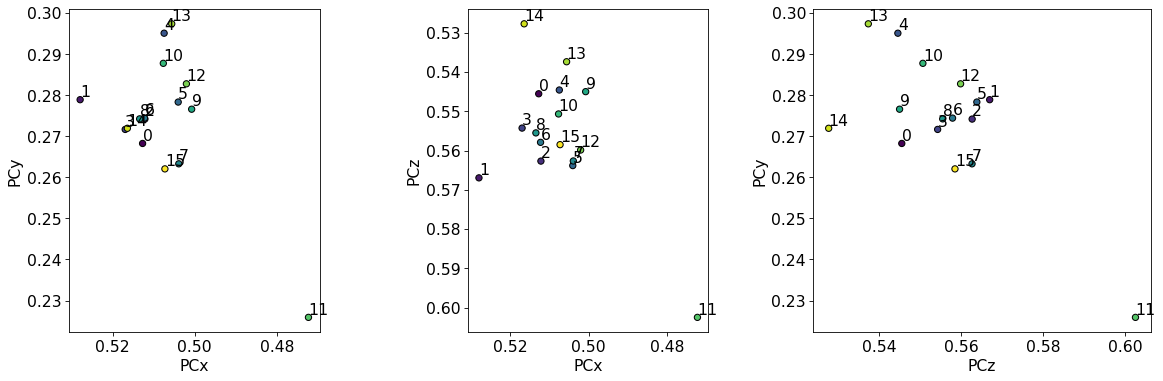
The PCs are quite dispersed, but most seem to cluster around an average PC. We should only use the average PC from these initial estimates and not try to fit a plane to them, as they do not vary in the grid they were extracted from.
Index the grid patterns using Hough indexing with the initially estimated PCs (to be averaged later!)
[16]:
indexer = det_grid.get_indexer(
pl,
reflectors=[[1, 1, 1], [2, 0, 0], [2, 2, 0], [3, 1, 1]],
rSigma=2,
tSigma=2,
)
[17]:
xmap_grid = s_grid.hough_indexing(pl, indexer=indexer, verbose=2)
Hough indexing with PyEBSDIndex information:
PyOpenCL: True
Projection center (Bruker, mean): (0.5077, 0.274, 0.556)
Indexing 16 pattern(s) in 1 chunk(s)
Radon Time: 0.007226542002172209
Convolution Time: 0.025221042000339366
Peak ID Time: 0.009593624999979511
Band Label Time: 0.008179166994523257
Total Band Find Time: 0.0502801249967888
Band Vote Time: 0.0048961669963318855
Indexing speed: 234.73502 patterns/s
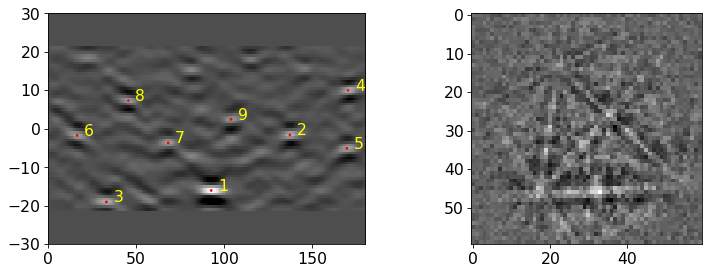
Plot the pattern fit (values in range [0, 3]) and confidence metric (values in the range [0, 1])
[18]:
fig, axes = plt.subplots(ncols=2, figsize=(12, 4))
for ax, to_plot, label in zip(
axes, ["fit", "cm"], ["Pattern fit [deg]", "Confidence metric"]
):
im = ax.imshow(xmap_grid.get_map_data(to_plot))
fig.colorbar(im, ax=ax, label=label, pad=0.02)
fig.subplots_adjust(wspace=0)
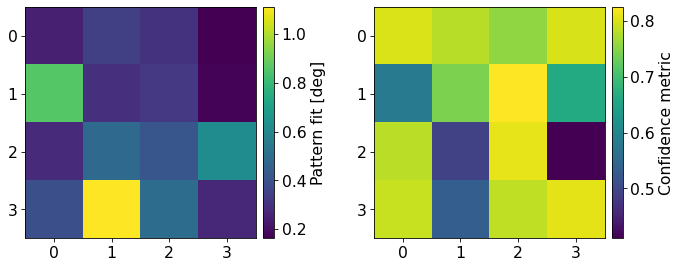
We see that PyEBSDIndex is fairly confident on the indexed solution for most patterns. Patterns with a low confidence seem to be located on boundaries in the IQ map above (4, 9, 11, and 13). These patterns have the highest pattern (mis)fit as well.
Let’s refine both the PCs and orientations using pattern matching (see the pattern matching tutorial for details). We use the Nelder-Mead implementation from the NLopt package, which is an optional dependency of kikuchipy (see the installation guide for details).
[19]:
xmap_grid_ref, det_grid_ref = s_grid.refine_orientation_projection_center(
xmap=xmap_grid,
detector=det_grid,
master_pattern=mp,
energy=20,
method="LN_NELDERMEAD",
trust_region=[5, 5, 5, 0.05, 0.05, 0.05], # Wide!
rtol=1e-7,
signal_mask=signal_mask,
# Recommended when refining few patterns
chunk_kwargs=dict(chunk_shape=1),
)
Refinement information:
Method: LN_NELDERMEAD (local) from NLopt
Trust region (+/-): [5. 5. 5. 0.05 0.05 0.05]
Relative tolerance: 1e-07
Refining 16 orientation(s) and projection center(s):
[########################################] | 100% Completed | 423.98 ms
Refinement speed: 37.31718 patterns/s
Print normalized cross-correlation (NCC) scores, number of evaluations (iterations) and the mean and standard deviation of the refined (PCx, PCy, PCz)
[20]:
0.48248586244881153
557.375
[0.50806911 0.26416428 0.56198178]
[0.00819355 0.0075463 0.01164782]
Plot the refined PCs as we did above
[21]:
det_grid_ref.plot_pc("scatter", annotate=True)
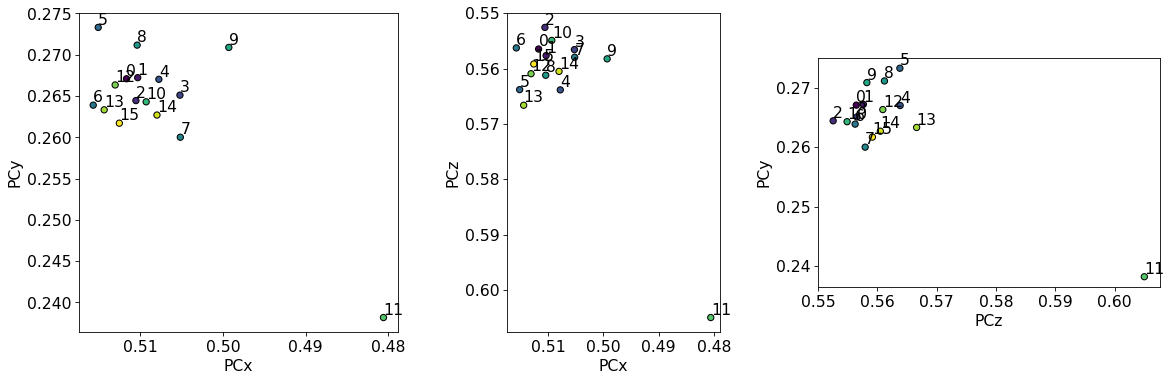
The PCs are still quite spread out, but the deviations from the mean are much smaller compared to the PCs from Hough indexing alone.
Let’s plot the NCC score
[22]:
xmap_grid_ref.plot(
"scores",
remove_padding=True,
colorbar=True,
colorbar_label="NCC",
figure_kwargs={"figsize": (4, 4)},
)
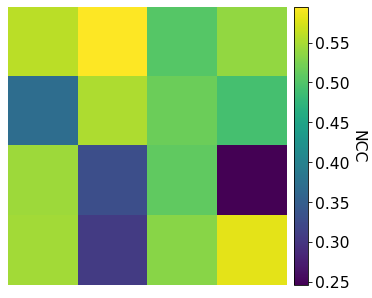
Let’s inspect the refined orientations by plotting center lines of the Kikuchi bands on top of patterns (see the geometrical EBSD simulations tutorial for details)
[23]:
g = ReciprocalLatticeVector.from_min_dspacing(phase, 1)
g.sanitise_phase() # Expand unit cell
g.calculate_structure_factor()
F = abs(g.structure_factor)
g = g[F > 0.5 * F.max()]
g.print_table()
h k l d |F|_hkl |F|^2 |F|^2_rel Mult
1 1 1 2.034 11.8 140.0 100.0 8
2 0 0 1.762 10.4 108.2 77.3 6
2 2 0 1.246 7.4 55.0 39.3 12
3 1 1 1.062 6.2 38.6 27.6 24
[24]:
Get simulations
[25]:
sim = simulator.on_detector(
det_grid_ref, xmap_grid_ref.rotations.reshape(*xmap_grid_ref.shape)
)
Finding bands that are in some pattern:
[########################################] | 100% Completed | 105.75 ms
Finding zone axes that are in some pattern:
[########################################] | 100% Completed | 106.07 ms
Calculating detector coordinates for bands and zone axes:
[########################################] | 100% Completed | 107.12 ms
Plot geometrical simulations on top of patterns
[26]:
fig, axes = plt.subplots(
nrows=grid_shape[0], ncols=grid_shape[1], figsize=(12, 12)
)
for i, rc in enumerate(np.ndindex(grid_shape)):
axes[rc].imshow(s_grid.data[rc] * ~signal_mask, cmap="gray")
axes[rc].axis("off")
lines = sim.as_collections(rc)[0]
axes[rc].add_collection(lines)
axes[rc].text(1, 1, i, va="top", ha="left", c="w")
fig.subplots_adjust(wspace=0.03, hspace=0.03)
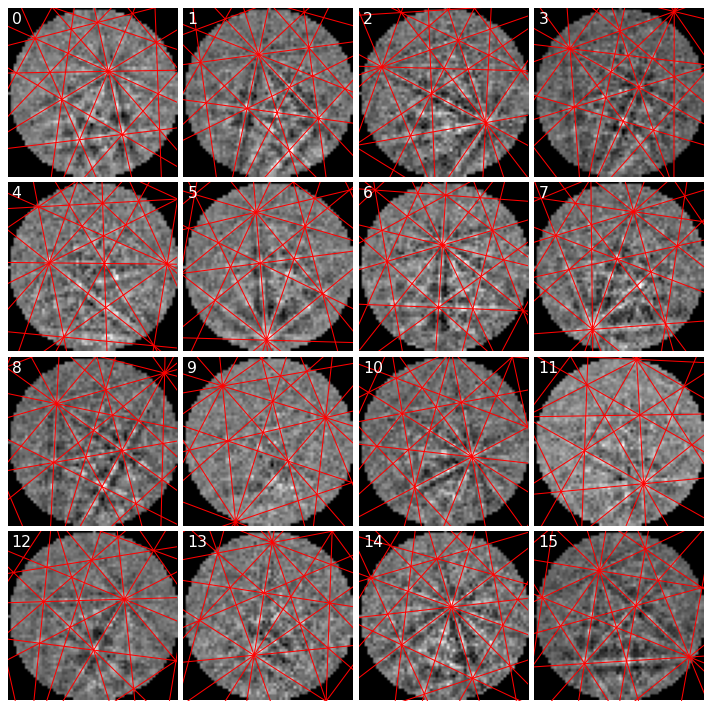
Most simulated lines seem lie on top of experimental bands, as expected.
Let’s now compute the average PC weighted by correlation scores
[27]:
det_ref = det_grid_ref.deepcopy()
det_ref.pc = np.average(
det_grid_ref.pc.reshape((-1, 3)), weights=xmap_grid_ref.scores, axis=0
)
print("Estimated PC:", det_ref.pc)
print("EDAX OIM PC: ", det.pc)
print("Difference: ", det_ref.pc - det.pc)
Estimated PC: [[0.50921821 0.26499808 0.56032179]]
EDAX OIM PC: [[0.50726193 0.26207614 0.55848867]]
Difference: [[0.00195628 0.00292194 0.00183312]]
We see that the PC we obtained with our routine above deviates little from the EDAX OIM PC. This is not surprising since we used the EDAX OIM PC as an initial guess. Based on the geometrical simulations above, these PC values seem OK.
Index all patterns with Hough indexing#
Let’s index the entire map of patterns with PyEBSDIndex, using our indexer from before but with the new estimated PC
[28]:
indexer = det_ref.get_indexer(pl, g.unique(True), rSigma=2, tSigma=2)
indexer.PC
[28]:
array([0.50921821, 0.26499808, 0.56032179])
[29]:
xmap = s.hough_indexing(pl, indexer=indexer, verbose=1)
Hough indexing with PyEBSDIndex information:
PyOpenCL: True
Projection center (Bruker): (0.5092, 0.265, 0.5603)
Indexing 28086 pattern(s) in 54 chunk(s)
Radon Time: 2.4334475409414154
Convolution Time: 1.9678099150041817
Peak ID Time: 0.7000535420229426
Band Label Time: 0.5577443299553124
Total Band Find Time: 5.6625450830033515
Band Vote Time: 1.0612132920068689
Indexing speed: 4157.15925 patterns/s
[30]:
xmap
[30]:
Phase Orientations Name Space group Point group Proper point group Color
-1 5 (0.0%) not_indexed None None None white
0 28081 (100.0%) ni Fm-3m m-3m 432 tab:blue
Properties: fit, cm, pq, nmatch
Scan unit: um
Let’s plot the inverse pole figure (IPF)-Z color map. First, we must get a color key, potentially setting the sample direction if we want another IPF than IPF-Z
[31]:
pg = xmap.phases[0].point_group
ckey_m3m = plot.IPFColorKeyTSL(pg)
print(ckey_m3m)
IPFColorKeyTSL, symmetry: m-3m, direction: [0 0 1]
Plot the map with the IPF color key next to the map
[32]:
# Make an array of full map size of zeros (black), and fill colors from
# successfully indexed nickel in the correct points
rgb = np.zeros((xmap.size, 3))
rgb[xmap.is_indexed] = ckey_m3m.orientation2color(
xmap["indexed"].orientations
)
fig = xmap.plot(rgb, remove_padding=True, return_figure=True)
# Place color key next to map
rect = [1.04, 0.115, 0.2, 0.2] # [Left, bottom, width, height]
ax_ckey = fig.add_axes(rect, projection="ipf", symmetry=pg)
ax_ckey.plot_ipf_color_key(show_title=False)
ax_ckey.patch.set_facecolor("None")

We see that Hough indexing with PyEBSDIndex is able to index the patterns quite convincingly.
Fit PC in vertical direction#
Finally, we’ll refine orientations and PCs in a vertical slice, average the PCs in the horizontal direction, and inspect the PCs and PC errors as a function of the vertical position. We’ll use the same vertical slice as [Pang et al., 2020] use.
[33]:
# Get tuple of slices to extract data of interest
x0, x1 = 84, 84 + 10
y0, y1 = 0, xmap.shape[0]
slices = (slice(y0, y1), slice(x0, x1))
# Rectangle to highlight the slice on top of IPF-Z map
rect_slice = mpatches.Rectangle(
xy=(x0, y0 - 1),
width=x1 - x0,
height=y1 - y0,
color="k",
alpha=0.3,
)
fig.axes[0].add_artist(rect_slice)
fig # Show the figure again
[33]:

Create a navigation mask to only index the patterns within this slice. Navigation and signal masks in kikuchipy follow the convention in other packages like NumPy, where points to mask out are set to True.
[34]:
Before going further, it is important to set the binning factor and (unbinned) detector pixel size
[35]:
det_ref.binning = 8
det_ref.px_size = 59.2
We’ll use the exact same trust region (+/- bounds) on the orientations (1\(^{\circ}\)) and PCs in EMsoft’s convention (5 px for \(x_{pc}\) and \(y_{pc}\) and 500 \(\mu\)m for \(L\)) in the refinement as used by [Pang et al., 2020].
[36]:
trust_region = [
1,
1,
1,
5 / (det_ref.ncols * det_ref.binning),
5 / (det_ref.nrows * det_ref.binning),
500 / (det_ref.nrows * det_ref.px_size * det_ref.binning),
]
Refine orientations and PCs of patterns in the slice, using the Hough indexed orientations and the estimated average PC as initial guesses
[37]:
xmap_slice_ref, det_slice_ref = s.refine_orientation_projection_center(
xmap=xmap,
detector=det_ref,
master_pattern=mp,
energy=20,
signal_mask=signal_mask,
navigation_mask=nav_mask,
method="LN_NELDERMEAD",
trust_region=trust_region,
rtol=1e-7,
)
Refinement information:
Method: LN_NELDERMEAD (local) from NLopt
Trust region (+/-): [1. 1. 1. 0.01042 0.01042 0.0176 ]
Relative tolerance: 1e-07
Refining 1510 orientation(s) and projection center(s):
[########################################] | 100% Completed | 32.31 ss
Refinement speed: 46.72735 patterns/s
Inspect the average NCC score, number of evaluations, and PC and the standard deviation of the average PC
[38]:
0.5480281793913304
544.4781456953642
[0.50968723 0.2662592 0.55946878]
[0.00345295 0.00330602 0.00274274]
To compare our results to those of [Pang et al., 2020], we will plot the PCs in EMsoft’s version 4 definition (see EBSDDetector.pc_emsoft() for details on the conversion from Bruker’s definition)
[39]:
pc_slice = det_slice_ref.pc_emsoft(version=4)
# Average horizontally
pc_slice_mean = pc_slice.mean(axis=1)
# Reshape for easy plotting
pcx, pcy, pcz = pc_slice_mean.reshape((-1, 3)).T
Get curves for the expected changes in PCs based on the equations given at the start
[40]:
y_pos_um = np.arange(y1) * xmap.dy
y_pos_px = y_pos_um / det_slice_ref.px_size
alpha = np.deg2rad(90 - det_slice_ref.sample_tilt + det_slice_ref.tilt)
# Find best intercept value for PCy and PCz by curve fitting
pcy_inter, _ = curve_fit(lambda y, a: a + np.cos(alpha) * y, y_pos_px, pcy)
pcz_inter, _ = curve_fit(lambda y, a: a + np.sin(alpha) * y, y_pos_um, pcz)
pcx_fit = np.ones(y_pos_um.size) * pcx.mean()
pcy_fit = pcy_inter[0] + np.cos(alpha) * y_pos_px
pcz_fit = pcz_inter[0] + np.sin(alpha) * y_pos_um
Get the distance (error) between measured and expected changes, and the cumulative fraction of these distances
[41]:
Let’s find out the 90th percentile error in each PC coefficient
[42]:
0.1480046790725208 0.1254626326395023 0.12014934204503748
As Pang and co-workers found, for \(x_{pc}\) and \(y_{pc}\), 90% of points have an error less than 0.2% of the detector width, while for \(L\), 90% of points have an error less than 0.15%.
Let’s plot the experimental and expected changes of the PCs along the vertical direction, along with the cumulative fractions. The experimental changes are colored according to the grain orientations within the vertical slice in the IPF-Z above (last column).
[43]:
rgb_slice = rgb.reshape(xmap.shape + (3,))[slices]
rgb_slice = rgb_slice[:, -1, :]
[46]:
# Common keyword arguments
scatter_kw = {"c": rgb_slice, "ec": "k", "clip_on": False}
scatter_set_kw = {"xlabel": "y-position [um]", "xlim": (0, y_pos_um[-1])}
plot_kw = {"lw": 2, "clip_on": False}
plot_set_kw = {"ylabel": "Cumulative fraction", "ylim": (0, 1)}
fig, axes = plt.subplots(nrows=2, ncols=3, figsize=(12, 6))
ax0, ax1, ax2, ax3, ax4, ax5 = axes.ravel()
# PC vs. y-position w/ best linear fit
ax0.scatter(y_pos_um, pcx, **scatter_kw)
ax1.scatter(y_pos_um, pcy, **scatter_kw)
ax2.scatter(y_pos_um, pcz, **scatter_kw)
ax0.plot(y_pos_um, pcx_fit, c="k")
ax1.plot(y_pos_um, pcy_fit.ravel(), c="k")
ax2.plot(y_pos_um, pcz_fit.ravel(), c="k")
ax0.set(ylabel="xpc [px]", ylim=(0, 10), **scatter_set_kw)
ax1.set(ylabel="ypc [px]", ylim=(108, 118), **scatter_set_kw)
ax2.set(ylabel="L [um]", ylim=(15600, 16200), **scatter_set_kw)
# Cumulative fraction of deviations
ax3.plot(pcx_err_sorted, y_cum, **plot_kw)
ax4.plot(pcy_err_sorted, y_cum, **plot_kw)
ax5.plot(pcz_err_sorted, y_cum, **plot_kw)
ax3.set(xlabel="xpc error [px]", xlim=(0, 2), **plot_set_kw)
ax4.set(xlabel="ypc error [px]", xlim=(0, 2), **plot_set_kw)
ax5.set(xlabel="L error [um]", xlim=(0, 100), **plot_set_kw)
fig.tight_layout()
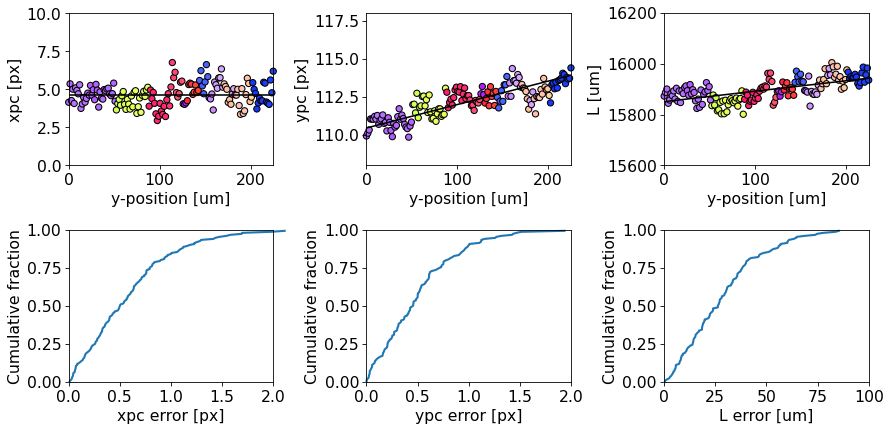
There are clear systematic deviations in the PC away from the expected PC caused by grain orientations. See the discussion by [Pang et al., 2020] for possible causes of this and more details on the above analysis.
In conclusion, coming back to the point made in the beginning: whenever possible, we should estimate a PC from not only many patterns, but also from many patterns from different grains.